











































































Neu Registrieren
Ich habe noch kein Benutzerkonto und möchte mich kostenlos registrieren.
Zur Registrierung
Large Language Models vs. Thrombose-Spezialist:innen
Künstliche Intelligenz auf Expertenniveau
8. Januar 2026
Große Sprachmodelle (Large Language Models, LLM) haben in verschiedenen medizinischen Disziplinen beeindruckende Fähigkeiten gezeigt, ihre Leistungsfähigkeit im Bereich Thrombose und Hämostase war bislang jedoch nicht untersucht. Angesichts der Tatsache, dass die venöse Thromboembolie (VTE) die dritthäufigste kardiovaskuläre Erkrankung darstellt, könnte der Einsatz von KI-basierten Tools, welche die Aufklärung der Patient:innen erleichtern und die klinische Entscheidungsfindung unterstützen, die Belastung durch VTE sowohl für die Patient:innen als auch für das Gesundheitssystem verringern. Trotz der Fortschritte werden LLM im klinischen Alltag weiterhin mit Zurückhaltung eingesetzt. Hauptgründe sind offene Fragen zu Datenschutz und ethischem Umgang mit Patientendaten sowie die Gefahr von fehlerhaften oder medizinisch nicht aktuellen Antworten. Die Wiener Forscher:innen untersuchten in ihrer Studie die Performance von LLM im Vergleich zu VTE-Expert:innen, einschließlich eines direkten Head-to-Head-Vergleiches der Antworten. Zudem analysierten sie, ob Ärzt:innen KI-generierte von menschlichen Antworten unterscheiden können, wie schnell neue Evidenz in den LLM abgebildet wird und ob deren Antworten potenziell einen Schaden für Patient:innen verursachen könnten.
Drei Expert:innen, drei LLM
Drei international renommierte Expert:innen für Thrombose und Hämostase beantworteten insgesamt sechs Fragen: drei häufige Patientenanfragen und drei komplexe klinische Fallvignetten. Parallel bearbeiteten drei LLM die gleichen Fragen: ChatGPT-4.5, Le Chat Pixtral Large und DeepSeek-R1. Die eingesetzten LLM wurden aufgrund ihrer weiten Verbreitung ausgewählt, zudem wurden die Modelle in drei unterschiedlichen Ländern entwickelt. Dies lässt vermuten, dass sie mit verschiedenen Datensätzen und Leitlinien trainiert wurden. Da sich in Vorabtests zeigte, dass LLM zu sehr ausführlichen Antworten neigen und, um mögliche Rückschlüsse allein aufgrund der Länge zu vermeiden, wurde die Antwortlänge auf zwei Sätze limitiert. 37 Ärzt:innen aus 18 Ländern mit Erfahrung im VTE-Management bewerteten diese Antworten verblindet auf einer Skala von 1 („sehr unzureichend“) bis 10 („ausgezeichnet“) hinsichtlich ihrer Angemessenheit und schätzten zusätzlich ein, ob die Antwort von einem Menschen oder einem LLM stammte.
Patientenaufklärung und klinische Entscheidungsfindung
Über alle sechs getesteten Fragen hinweg lieferten die KI-Modelle signifikant höhere Scores im Hinblick auf die Angemessenheit der Antworten als die Expert:innen (Median 8,0 vs. 7,0; p < 0,001; Abb.). Keine der Antworten (weder von LLM noch von Menschen generiert) war nach Beurteilung der Expert:innen potenziell gefährlich für Patient:innen.
In der Patientenaufklärung erzielten alle drei LLM deutlich höhere Scores als die Expert:innen. Die LLM lagen im Durchschnitt +1,6 bis +1,9 Punkte über den Expert:innen; zwischen den einzelnen LLM fanden sich keine Unterschiede. Die Anzahl an verwendeten Wörtern war zwischen LLM und Expert:innen vergleichbar. Ein differenzierteres Bild zeigte sich bei der klinischen Entscheidungsfindung: DeepSeek-R1 schnitt hier signifikant besser ab als die Expert:innen (95%-KI: 1,1–1,8; korrigiertes p < 0,001), während ChatGPT-4.5 und Le Chat Pixtral Large ein mit den Fachexpert:innen vergleichbares Niveau erreichten. Eine explorative Analyse einer Fallvignette eines krebskranken Patienten mit tiefer Venenthrombose ergab, dass nach sechs Monaten DOAK-Therapie — mit der Frage zur Dosisreduktion — keines der drei LLM die vor drei Wochen publizierte API-CAT-Studie in seiner Entscheidung zur Therapieanpassung explizit erwähnte; dennoch hatten die LLM bereits vor der Publikation eine Dosisreduktion vorgeschlagen, was mit den Studienergebnissen kongruent ist.
Ob eine Antwort von einem Menschen oder einem LLM stammte, konnten die Ärzt:innen im Durchschnitt nicht zuverlässig erkennen. Bei Patientenanfragen wirkte Le Chat Pixtral Large sogar „menschlicher“ als die Expert:innen, während DeepSeek-R1 bei klinischen Entscheidungen am „menschlichsten“ bewertet wurde.
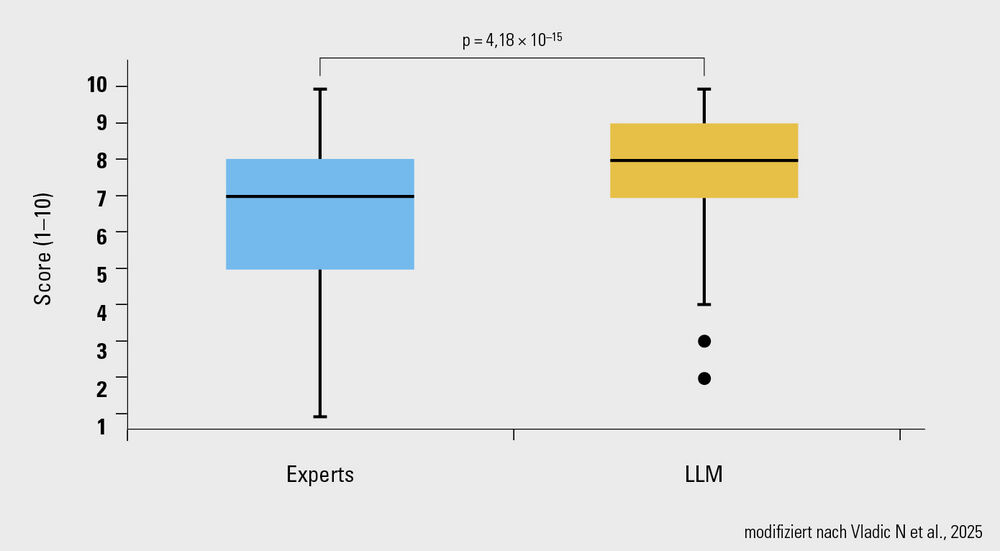
Abb.: Vergleich der Scores zur Angemessenheit der Antworten
LLM als unterstützende Werkzeuge
Die Studie demonstriert, wenngleich an einer kleinen Zahl an Fragen, dass LLM bei Fragen zu venösen Thromboembolien in der Patientenaufklärung und klinischen Entscheidungsfindung die Leistung von Expert:innen erreichen oder übertreffen. Die Ergebnisse unterstreichen das Potenzial solcher KI-basierten Sprachmodelle als unterstützende Werkzeuge, da sie medizinisches Wissen schnell abrufen können, klare Handlungsempfehlungen formulieren oder auch administrative Aufgaben effizient unterstützen. Allerdings werden neue wissenschaftliche Erkenntnisse nur verzögert berücksichtigt, Fehler sind möglich und kommen oft vor, und eine zu starke Abhängigkeit (insbesondere bei jungen Mediziner:innen) kann die eigene klinische Urteilskraft beeinträchtigen. LLM sollten daher primär als Hilfsmittel eingesetzt werden, während die Verantwortung bei den behandelnden Ärzt:innen verbleibt.

Ursprünglich erschienen:
UIM 10|2025
UIM 10|2025
Publikationsdatum: 2025-12-18
Zur Ausgabe »
Zur Ausgabe »
Bildnachweis
Vorschaubild: Bordinthorn - stock.adobe.com