














































































Neu Registrieren
Ich habe noch kein Benutzerkonto und möchte mich kostenlos registrieren.
Zur Registrierung
E-Cardiology und Digital Health
23. Oktober 2018
Wie viele Fachgesellschaften hat die European Society of Cardiology (ESC) schon lange erkannt, dass moderne Informationstechnologie in der Lage ist, die medizinische Forschung und Praxis grundlegend zu verändern. Insofern gab es auch zahlreiche Vorträge zum Thema „E-Cardiology/Digital Health“ am diesjährigen ESC-Kongress in München.
Die von diversen Institutionen, Kliniken, aber auch tragbaren Sensoren bereitgestellten Daten sind die Basis für viele neue Möglichkeiten, welche es erlauben, individuell auf den Patienten zu reagieren sowie neue unbekannte Muster in den Daten zu entdecken.
Digital Health sowie Big Data bieten – in Verbindung mit diesen neuen Technologien – den Medizinern eine Chance für eine bessere und effizientere Versorgung. Es muss jedoch beachtet werden, dass die Daten und Informationen schneller anwachsen, als sie derzeit verarbeitet und analysiert werden können. Eines der grundlegenden Probleme ist, dass über 80 % der anfallenden Daten in unstrukturierter Form vorliegen und erst in eine adäquate Form gebracht werden müssen, bevor überhaupt Informationen und neue Erkenntnisse extrahiert werden können.
Genau hier helfen Algorithmen aus dem Gebiet der künstlichen Intelligenz. Die Angst, dass in Zukunft Algorithmen die Arbeit von Ärzten übernehmen könnten, schwebt dabei im Raum. Dies erscheint den Autoren jedoch als unbegründet. Offensichtlich ist, dass das Verhältnis zwischen Arzt und Patient von zentraler Bedeutung in der Gesundheitsversorgung bleibt. Je genauer und intensiver der Kontakt zum Patienten ist, umso höher wird die Qualität der Behandlung sein, wodurch die Kosten im Gesundheitssystem auf lange Sicht sogar gesenkt werden können.
Precision Health
Gewöhnlich werden Medikamente und Therapien für den durchschnittlichen Patienten (zumeist männlich und von weißer Hautfarbe) entwickelt. Eine für den Patienten individualisierte Therapie wäre wünschenswert, ist jedoch mit extremen Kosten verbunden, weshalb die Industrie bisher kein großes Interesse daran zeigte. Hier können biologische Data Warehouses – gekoppelt mit intelligenten Verfahren – helfen, diesen Schritt der individuellen Therapie mit adäquaten Ressourcen zu gehen. Ein Data Warehouse im Bereich Life Sciences enthält u. a. detaillierte metabolische, proteomische und genomische Daten, Annotationen und Publikationen, um Biomarker und System-Biologie-Ansätze zu untersuchen. Das Data Warehouse ist als eine fachlich orientierte, integrierte, nichtflüchtige und fachlich interpretierte Sammlung integrierter Daten definiert.1 Die Rohdatensätze werden transformiert, bereinigt und mit detaillierteren Informationen angereichert, um derartige patientenzentrierte Analysen und Therapien ermöglichen zu können.
Digital Health
Digital Health umfasst jene Bereiche der Informationstechnologie, welche in der Lage sind, für die aktuellen Gesundheitsprobleme eine Lösung zu finden. Hier kommen Sensoren bzw. generell Hardwarelösungen sowie Softwarekomponenten zum Einsatz, um Patienten und Angehörige im Umgang mit Krankheiten und Gesundheitsrisiken zu unterstützen und schnellstmöglich auf eine sich verändernde Situation reagieren zu können. In diesem Fall kommen Wearable Devices (also tragbare Geräte) zum Einsatz, in denen spezielle Sensoren integriert sind, die den Zustand vitaler Parameter sowie generelle Umgebungsinformationen sammeln und überwachen, um diese anschließend mittels Telemonitoring an eine zentrale Stelle zur Auswertung zu übertragen. Ist es nicht möglich, mittels externer Sensoren die notwendigen Daten zu erfassen, so kommen implantierbare Sensoren zu Anwendung. Derzeit werden beispielsweise solche Systeme bei kardialen Problemen (Arrhythmien, Herzinsuffizienz) verwendet. Ein Device wird dem Patienten in einem chirurgischen Eingriff implantiert, sammelt die anfallenden Daten und sendet diese wiederum via Telemonitoring an den behandelnden Arzt. Dieser kann eine adäquate Reaktion einleiten und hoffentlich eine Hospitalisierung verhindern. Ein weiteres Beispiel sind künstliche Hüftgelenke, welche mittels Sensorik in der Lage sind, Bewegungs- und Belastungsdaten zu erfassen und zu übermitteln. Generell gilt, dass implantierbare aktive Devices immer von einer Energieversorgung abhängig sind und somit eine Laufzeitlimitation für die Datenerhebung und Übermittlung besteht.
Gefahren
Bei allen Vorteilen der digitalen Medizinrevolution darf jedoch nicht auf den Datenschutz vergessen werden. Die Bedenken der Datenschützer sind, dass Gesundheits- und personenbezogene Daten ausgespäht und missbräuchlich verwendet werden. Gerade die „Big Player“ wie Google, Apple, Microsoft haben Interesse an solchen Daten, um ihre Geschäftsfelder weiter ausbauen zu können. Daher braucht es klare regulatorische Richtlinien.
Big Data: strukturierte und unstrukturierte Daten
Unter Big Data versteht man große, komplexe Datenmengen, welche häufig in schwach strukturierter Form vorliegen. Nach Vorverarbeitung der Daten wird eine Analyse mittels verschiedener biostatistischer Verfahren durchgeführt. Ziel dabei ist es, unbekannte Muster und Informationen zu entdecken.
Ein großes Problem in der Medizin ist, dass vorliegende Daten zum Großteil in unstrukturierter Form vorhanden sind. Generell gibt es drei Arten von Daten:
- strukturierte Daten, die mittels Abfragesprachen direkt für Analysen extrahiert werden können
- semistrukturierte Daten, die eine schwach vorliegende Struktur aufweisen und eine Transformation vor Verarbeitung notwendig machen
- unstrukturierte Daten, die beispielsweise in gewöhnlichen Dokumenten, Arztbriefen etc. vorliegen. Um mit solchen Daten und Informationen automatisiert arbeiten zu können, bedarf es einer expliziten Vorverarbeitung. Bei dieser Vorverarbeitung werden die relevanten Daten extrahiert, in strukturierte Form gebracht und mit den anderen zur Verfügung stehenden Daten zusammengeführt. Für die Extraktion der Daten aus Texten kommen sprachwissenschaftliche Verfahren wie Natural-Language-Processing-Verfahren zum Einsatz.
Künstliche Intelligenz (KI) spielt in der Medizin eine immer wichtigere Rolle.2 Die anfallenden Datenmengen wachsen derart schnell, dass sich diese ohne künstliche Intelligenz nicht mehr bewältigen lassen. Als Beispiel sei radiologisches Bildmaterial angeführt. Ein Radiologe ist in der Lage, aus den diversen Bildschichten eine klare Diagnose zu erstellen, um anschließend die notwendige Behandlung einzuleiten. Mittels künstlicher Intelligenz, also Algorithmen, welche über den Verlauf der Zeit dazulernen und sich konsekutiv in ihrer Leistung verbessern, werden diese Bilder automatisiert analysiert und befundet. Somit bietet die künstliche Intelligenz im Bereich der Radiologie dem Arzt eine Unterstützung an. Dieser hat folglich die Möglichkeit, sich nach automatisierter Vorbefundung wesentlich intensiver dem Patienten zu beschäftigen.
In den Patientendaten gibt es viele verschiedene Variablen, die interpretiert werden müssen, um damit die individuelle Patientenversorgung verbessern zu können. Mittels KI-Algorithmen wird es möglich, sowohl adaptive als auch prädiktive Modelle zu erzeugen. KI-Algorithmen können in „supervised learning“ und „unsupervised learning“ unterteilt werden. „Unsupervised learning“ konzentriert sich darauf, die zugrunde liegende Struktur im bestehenden Datensatz zu finden, während „supervised learning“ zur Erstellung prädiktiver Modelle verwendet wird. Neuronale Netzwerke ermöglichen nichtlineare Klassifizierungen mit mehrerer Schichten (hidden layers). Diese versuchen, die aus dem Lernprozess resultierende Klassifizierungsfunktion zu optimieren. In der Abbildung ist ein solches Netzwerk zur Prädiktion der Lokalisation des akzessorischen Bündels beim WPW-Syndrom abgebildet.
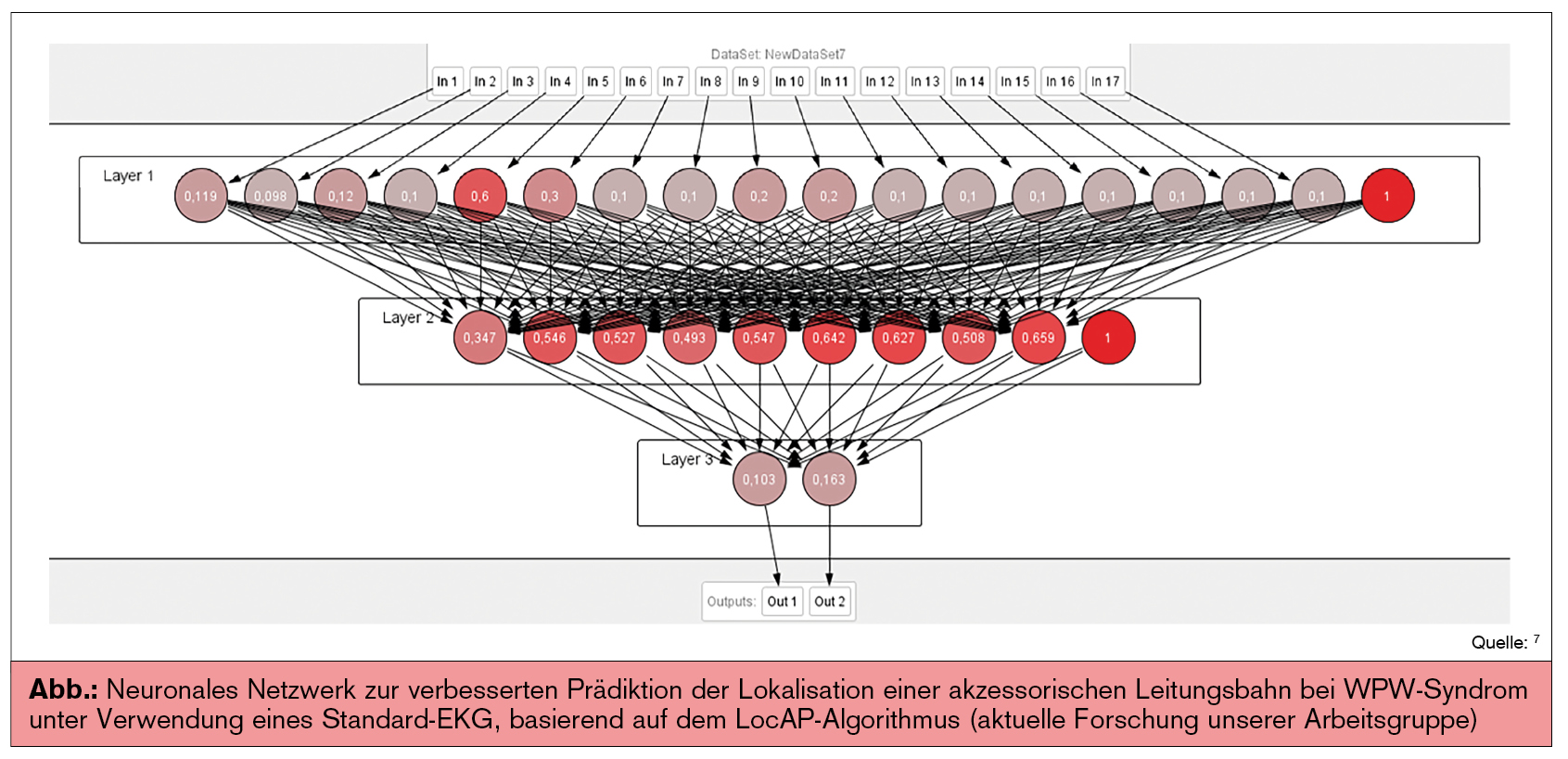
Deep Learning ist eine Methode, die es ermöglicht, komplexe hierarchische Darstellungen aus einem Trainingsset zu lernen. Deep Learning wird bereits seit längerem in der Informatik verwendet und hat aufgrund der Performance in der Medizininformatik neue Möglichkeiten eröffnet. Insbesondere in der Datenverarbeitung und Bilderkennung ist dieses Verfahren heute bereits weit verbreitet. So wurden beispielsweise rezent in der Kardiologie diese Algorithmen zur Messung des linksventrikulären Volumens mittels Magnetresonanzbildern3 bzw. zur nichtinvasiven Bestimmung der FFR in verengten Koronararterien mittels MSCT4 eingesetzt. Reinforcement-Learning-(RL-) Algorithmen5 sind sogenannte „Learning by trial and error“-Algorithmen. Hierbei werden sowohl die Eingabedaten als auch das Endergebnis für das Training verwendet. Je besser das RL-System trainiert wird (d. h. je mehr Fälle dem Algorithmus zugeführt werden), desto genauer ist das vorgeschlagene Ergebnis.
Ausblick
Digitale Medizin, bestehend aus den Bereichen e-Health & Big Data, ermöglicht durch künftige Entwicklungen eine personalisierte Medizin und einen Wissensgewinn zum Wohle der Patienten bei gleichzeitiger Reduktion der Gesundheitskosten. Aufgrund der explosionsartig anwachsenden Datenmengen steht die Informatik vor großen Herausforderungen, die es zu lösen gilt.
Komplexe Softwareprogramme werden dem Arzt in zahlreichen Punkten überlegen sein, diesen jedoch nicht ersetzen können. Denn Medizin ist bekanntermaßen mehr als nur Dateninterpretation. Um es frei nach dem bekannten Kardiologen Bernard Lown auszudrücken: „Wenn alles andere – auch Digital Health – versagt, dann unterhalte Dich mit dem Patienten“.6
1 Kimball R et al., Kimball’s Data Warehouse Toolkit
2 Johnson KW et al., J Am Coll Cardiol 2018; 71:2668–79
3 Avendi MR et al., Med Image Anal 2016; 30:108–19
4 Coenen A et al., Circ Cardiovasc Imaging 2018; 11:e007217
5 Sutton RS, Barto AG, Reinforcement Learning. An Introduction (Adaptive Computation and Machine Learning)
6 Schulz T, Zukunftsmedizin. DER SPIEGEL
7 Rantner LJ et al., Methods Inf Med 2012; 51:3–12

AutorIn: Priv.-Doz. DDr. Wolfgang Dichtl
Klinische Abteilung für Kardiologie und Angiologie,Universitätsklinik für Innere Medizin III. Medizinische Universität Innsbruck

AutorIn: Univ.-Doz. Dipl.-Ing. Dr. Bernhard Pfeifer
Institut für Elektrotechnik und Biomedizinische Technik, Private Universität für Gesundheitswissenschaften, Medizinische Informatik und Technik (UMIT), Hall in Tirol

Ursprünglich erschienen:
UIM 08|2018 Themenheft ESC
UIM 08|2018 Themenheft ESC
Herausgeber: o. Univ.-Prof. Dr. Günter J. Krejs
Zur Ausgabe »
Zur Ausgabe »